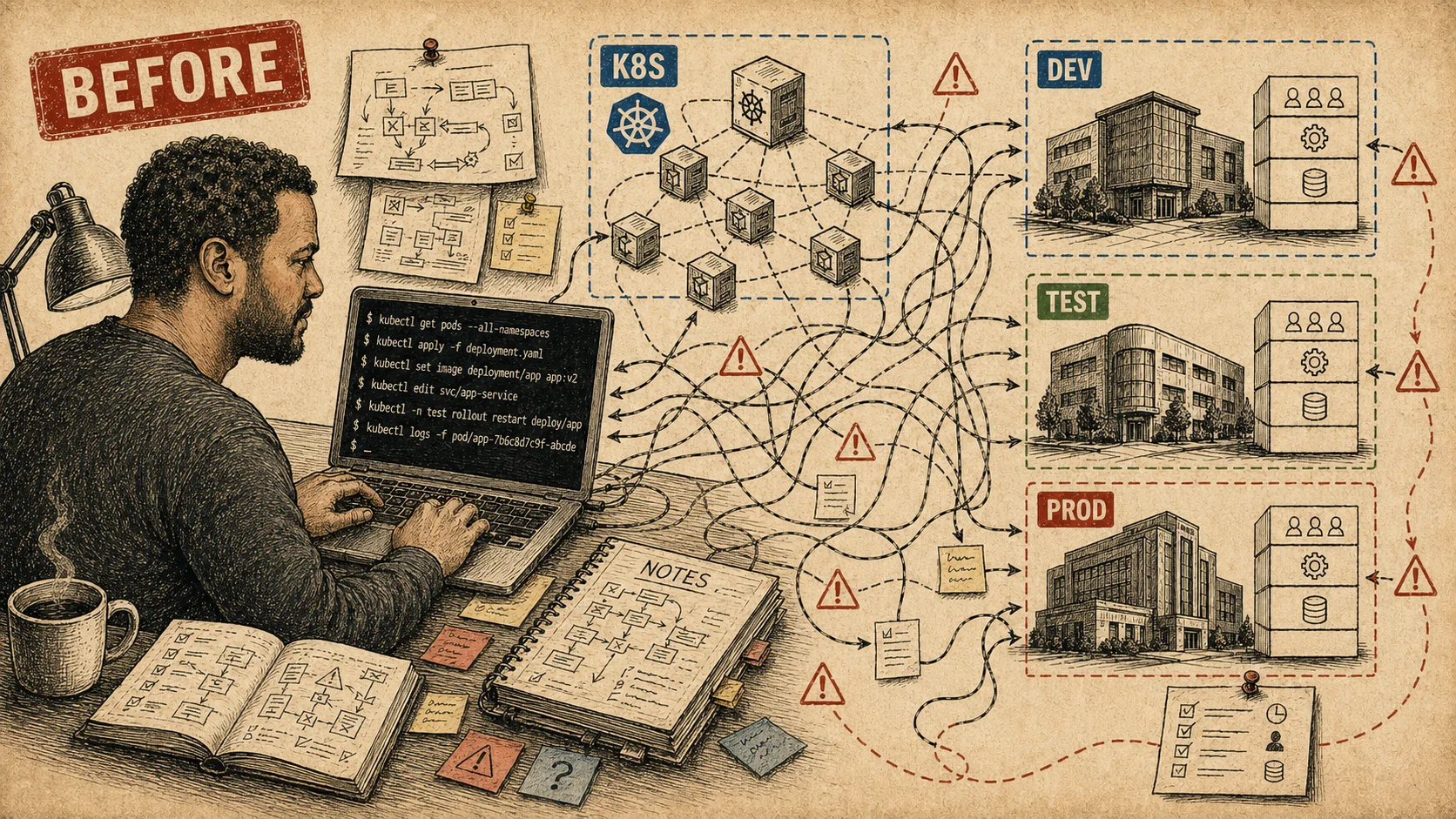
A working cluster and a team that still needed me to operate it
Making the cluster less dependent on me.
Archibus was running in Kubernetes. Now someone other than me had to be able to operate it.
The research cluster proved that Archibus could run in Kubernetes with a self-hosted identity layer and real SAML SSO. It also exposed the next problem: I was the only person who could operate it.
A team platform can't depend on one person's shell history. When a shared dev environment
drifted or broke, someone had to find me. I handled each deployment. Anyone trying to
work out what was running, or why, needed the context in my head. kubectl
wasn't a team interface under those conditions.
Runbooks helped, but they couldn't carry the whole job. Cluster state had to be visible enough for another person to read. Changes needed a path that worked without me sitting at the terminal.
Making Kubernetes less private
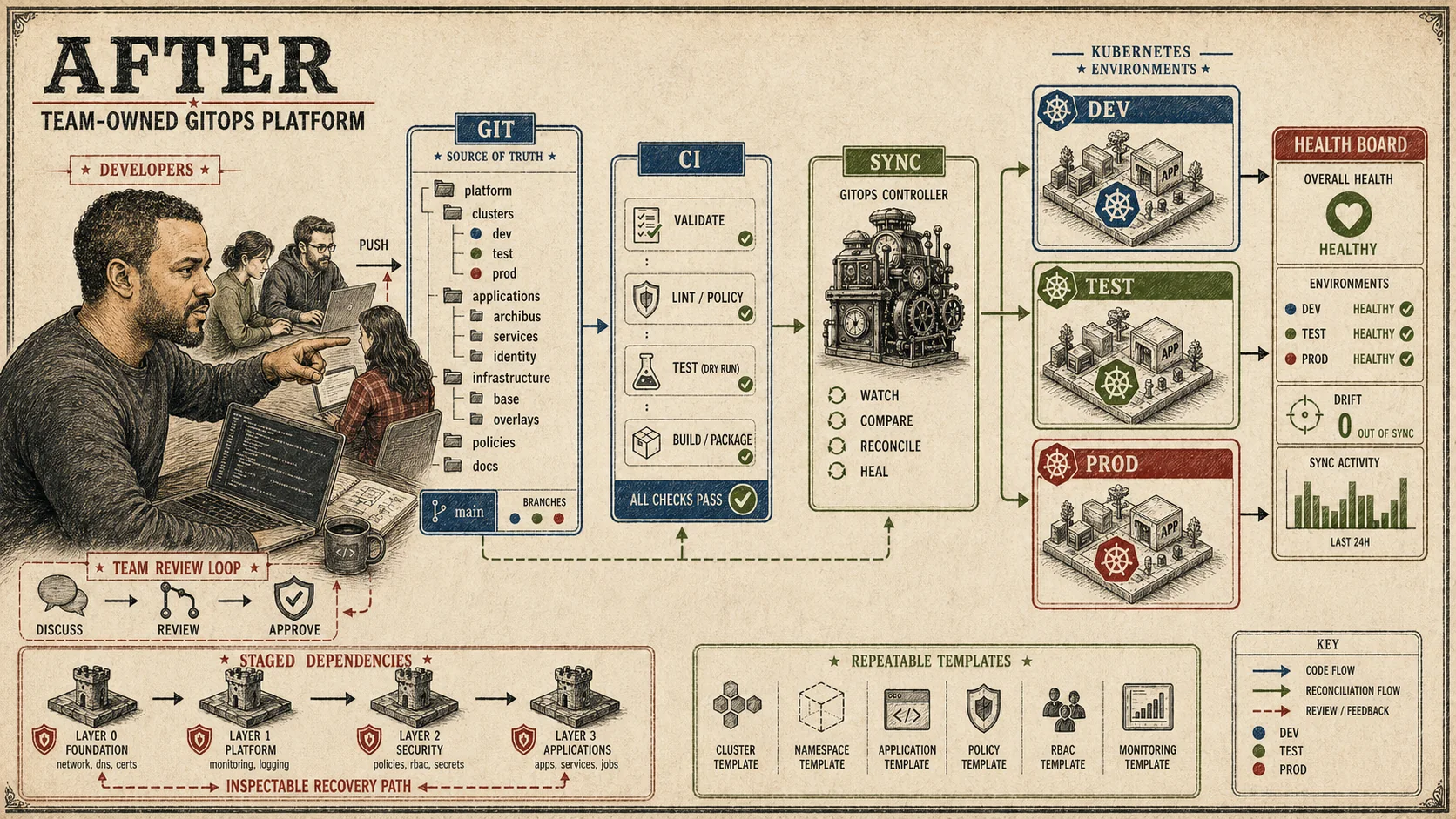
ArgoCD gave the team visibility. From its UI, someone could see what was deployed, what changed, whether it was healthy, whether it matched the source repo, and which branch it tracked. A shell session from last week couldn't answer those questions for a person who wasn't there.
First, branch names got operational meaning. dev and staging
deployed automatically. main needed a manual gate before touching production.
Codifying that rule turned it into a workflow instead of a convention people had to
remember.
environments:
- name: dev
branch: dev
autoSync: true
- name: staging
branch: staging
autoSync: true
- name: prod
branch: main
autoSync: falseThe branch mapping still needed a repeatable environment shape. ApplicationSets let one template generate several environment-specific Applications from a list. A new persistent Archibus dev or test environment now followed the same pattern as the older ones. Nobody had to rebuild a one-off shell session from memory.
apiVersion: argoproj.io/v1alpha1
kind: ApplicationSet
spec:
generators:
- list:
elements:
- env: dev
branch: dev
namespace: archibus-dev
- env: test
branch: test
namespace: archibus-test
template:
spec:
source:
targetRevision: "{{branch}}"
path: overlays/archibus/{{env}}
destination:
namespace: "{{namespace}}"
The CI pipeline made the handoff concrete. Instead of running kubectl apply
directly, it pushed to the source branch and asked the GitOps controller to reconcile.
Direct apply had made the CI runner the deployment interface. The sync request moved that
job to the controller, where status, history, and drift were visible.
kubectl apply had left the useful history inside one
person's shell session.
git push origin dev
# CI validates the change, then asks the GitOps controller to reconcile.
argocd app sync archibus-dev
argocd app get archibus-devThe early ArgoCD work also added explicit RBAC, team branch-workflow docs, and a clear split between environments that auto-deployed and those that needed approval. Source and controller status could now answer questions that had gone to whoever touched the cluster last.
What it became
The model held through the dev cluster work and changed again in later environments. Those later environments eventually moved from the original ArgoCD pattern to Flux.
The order became explicit: base platform resources, supporting services, application releases, then follow-up jobs. That dependency graph lives in source. Nobody has to find the person who remembers the original decisions.
dependsOn fields say which resources must be ready before the next
ones run. With that order in a manifest, recovery doesn't require the original
architect to recite it.
apiVersion: kustomize.toolkit.fluxcd.io/v1
kind: Kustomization
metadata:
name: environment-helmreleases
spec:
dependsOn:
- name: environment-platform
- name: environment-secrets
wait: true
path: ./flux/environment/helmreleasesThat dependency order took about a year of environment work to earn. Bash scripts from the research cluster made the manual steps readable. The ArgoCD experiments exposed the gap between "what is deployed" and "what the repo says." Flux staging put the full bootstrap order somewhere anyone could inspect without a conversation.
I could stay in the system. I just couldn't keep being its only API.
The question hasn't changed since the first ArgoCD experiment. Can someone understand and repair an environment from source and controller status, or do they have to ask me? The parts that held up put the answer in source instead of one person's memory.